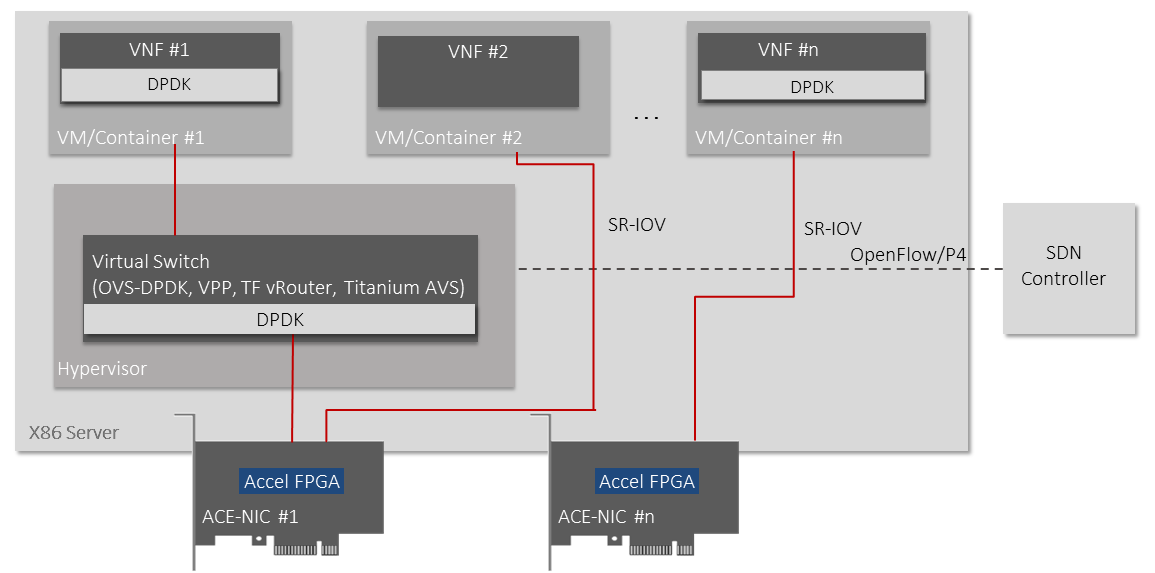
Ethernity provides NFVI acceleration by offloading data plane onto its ACE-NICs, integrated into NFVI architecture via DPDK, improving performance and TCO, especially at the network edge.
The Market Need
NFVI is responsible for communication between the network functions, storage, compute nodes, and management of a network. The ideal NFVI should be flexible, programmable, and easily automated, consisting of COTS compute and memory resources and a virtualization layer, providing no vendor lock-in and network disaggregation. However, a performance gap undermines network commoditization and virtualization, as the virtualization layer in the NFVI adds processing overhead that general-purpose server CPUs are not optimized to handle.
NFVI acceleration technologies for compute-intensive workloads are required to enhance CPU performance and improve operators’ TCO.
As virtualization and computation move from the central cloud toward the network edge, the NFVI platforms require additional optimization to meet power, space, and cooling constraints, especially for 5G use cases. Edge application requirements are more dynamic and require fast and full programmability supported only through FPGA-based SmartNICs.
Open Virtual Switching (OVS), in particular, demands full offload to accelerate the OVS and improve its performance. There is increasing demand for this in order to enable the flexibility of virtual switching with the high performance and low TCO of full hardware offload.
Other NFVI components, such as Titanium AVS, VPP and Tungsten Fabric, can also be offloaded to FPGA using the DPDK acceleration framework.
Our Offering
Ethernity’s ACE-NICs are easily integrated into NFVI architecture via standard DPDK APIs and offer NFVI acceleration through the offload of the data plane for advanced networking functions, including switching, routing, VxLAN processing; H-QoS; MPLS protocols and more. ACE-NIC SmartNICs provide high-speed packet processing, overlay tunnel termination, and data plane offload from CPU cores, all with significantly reduced CPU overhead and power.

- Highly adaptable to customer NFVI requirements through the use of standard DPDK APIs
- Deterministic and low latency performance, ASIC-like
- Fully programmable data path
- No vendor lock-in (DPDK API, any server, Any NFVI – Tungsten Fabric, VPP, Open vSwitch)
- Scalable with millions of entries for VxLAN, MPLS, and Layer 3 forwarding
- Extended H-QoS to support SLA with very high precision
FPGA Hardware Offload of NFVI and VNFs